A solid data governance strategy is founded on the ability to track and understand the flow of your data. Understanding your data with context allows you to identify data ownership, trace problems to their source, and discover all downstream consumers and the impact of each data product.
For example, if a financial report shows unexpected figures, tracking its journey in detail allows data teams to identify and correct the specific upstream process that caused the error, such as a faulty calculation in a database field.
Column-Level Lineage Defined
Column-level lineage is a fine-grained map of this flow. It’s a detailed visualization of how data moves and transforms throughout its lifecycle, from the data source (e.g. the data warehouse) to its destination (e.g. BI tools). With it, you can find dependencies of each table, column, or dashboard in your organization, so you can understand how data is being used and where it’s coming from.
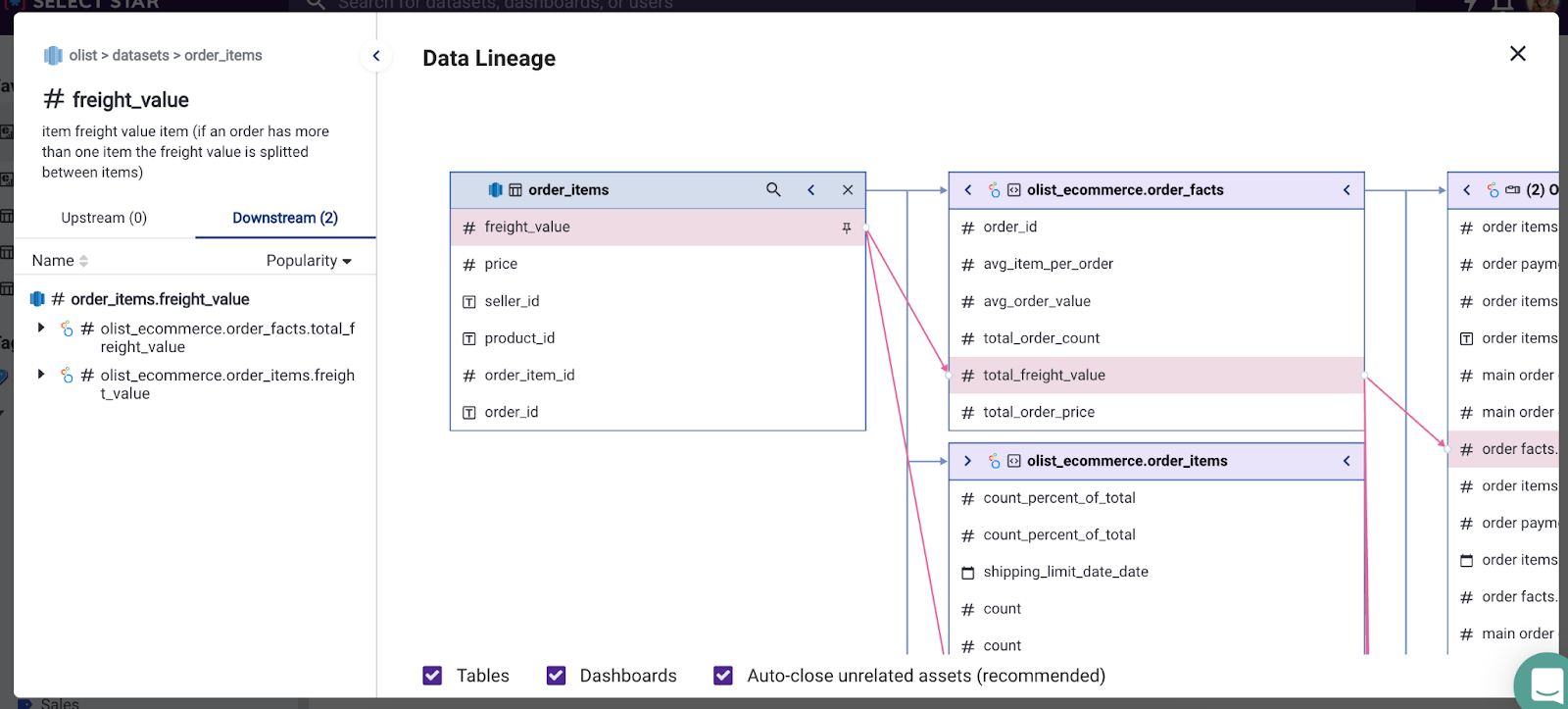
Column-level lineage enables you to see exactly how a particular field in a table was created and how it has transformed over time. This granularity is crucial since most SQL queries use specific column names rather than table names.
With materialized views and medallion data models that promote the denormalization of tables for faster querying, data teams easily end up in 100+ columns. In these cases, tracking lineage at the table level does not provide enough visibility when debugging broken dashboards or data pipelines.
Column-Level Lineage Use Cases
Column-level lineage can be used in a variety of ways to improve data quality and streamline data management processes. Here are some common use cases:
- Root cause analysis: Quickly pinpoint the source of data quality issues by tracking a data discrepancy back to a mistyped entry in a customer database or a miscalculated field in a sales report. For instance, if a financial report shows incorrect revenue figures, column-level lineage allows you to trace the data back through the analytics platform, the data warehouse, and ultimately to the original transactional system where an input error occurred. This accelerates error detection and resolution, as it allows you to isolate and address discrepancies directly at the source without the need for manual cross-referencing through various data layers.
- Impact analysis: Column-level data lineage provides a clear map of where data originates, how it's transformed, and where it's utilized across systems. When you understand the downstream impacts of those changes before you make them, you can avoid unintended consequences and make informed decisions about data management. For example, a financial institution might plan to update its customer data model. With column-level lineage, the institution can predict how these updates will affect its risk assessment algorithms and reporting processes. This foresight prevents costly errors in credit scoring and regulatory reporting by addressing potential issues before they materialize.
- Automated changes: Automate large-scale changes, such as schema migrations. Say you need to merge customer information from several acquired subsidiaries into its central CRM system. Column-level lineage informs scripts, so you can translate and consolidate data formats from different systems automatically. Now, customer records can be merged without duplicates or inconsistencies—a process that would otherwise be prone to error if done manually—minimizing downtime and manual errors.
- Cost optimization: Use column-level lineage to identify columns that are rarely used and deprecate them to optimize data storage and compute costs. Analyzing the lineage of data columns uncovers columns that are infrequently accessed or queried. These columns may be remnants of legacy operations or features that have since been deprecated but were never removed from the system. Armed with this detailed usage information, you can make informed decisions about which columns should be archived or deprecated altogether. This declutters the database which reduces the storage footprint and lowers the cost for data storage and computing.
Practical Applications of Column-Level Lineage
Column-level lineage is crucial for organizations that rely on data for decision-making. By tracing the origin and transformation of data from its source to its destination, companies ensure the accuracy and reliability of their data. These are a few practical applications of column-level lineage:
Root Cause Analysis
If dashboards look “off”, you can quickly find dependencies with automated column-level lineage. Instead of manually poring through SQL queries for hours to troubleshoot broken dashboards, column-level lineage provides a direct map to the source tables, allowing for an instant check on data accuracy and flow. Furthermore, by integrating lineage into CI/CD pipeline via API, one can preemptively detect and correct errors, simultaneously saving hours and maintaining data integrity.
Automated Data Propagation with PII Classification
Column-level lineage automates the propagation of column-level documentation and PII classification. Once a column containing PII is tagged, any downstream tables created from this data inherit the PII tag automatically, so all PII data is consistently identified and managed across all databases and reports. If a raw column's data definition changes, all downstream documentation, including PII classifications, will automatically update to reflect these changes, improving data quality and compliance efforts in tandem.
Data Modeling
Data modeling with column-level lineage allows for denormalized dataset optimization by identifying which columns are in use by downstream dashboards. This insight enables targeted refactoring, where you can streamline or remove underutilized columns, leading to leaner tables and faster queries.
Building Versus Buying a Column-Level Lineage Solution
When it comes to implementing a column-level lineage solution, you have two options: building your own or buying an existing tool.
While building your own solution may seem like a good idea, it can be expensive and resource-intensive. It’s a complex process, even for the most basic SQL queries, and requires a deep understanding of a company's data environment and dependencies. Even after building the solution, maintaining it can be a challenge, especially as your organization grows and your data stack becomes more complex.
On the other hand, buying an existing tool like Select Star's best-in-class column-level lineage solution can get you up and running in as little as 24 hours. Unlike other data lineage tools, Select Star’s in-depth analysis of column usage shows you if and how the data value has been used—whether it was transferred as-is, aggregated, or transformed—and points out which fields are being used for filters. Plus, our REST API allows you to merge information along with other metadata (e.g. popularity, top users, etc.) to build internal applications on top.
While it may seem tempting to build your own solution, the benefits of buying an existing tool far outweigh the costs and complexities of building and maintaining your own.
Best Practices for Setting Up Column-Level Lineage
When setting up column-level lineage, there are a few best practices that you should keep in mind to ensure that your metadata is accurate, up-to-date, and easy to understand.
Use Automated Data Lineage Capture
Unlike manual data lineage—which depends on individuals recording data flows by hand with spreadsheets or diagrams—automated data lineage solutions provide real-time insights into data flows and changes. This encompasses all data flows with more precision and speed, reducing the time it takes to resolve data quality issues to mere minutes.
Select the Right Tool For Your Organization
The ideal tool should seamlessly integrate into your data environment and enhance your data management capabilities. Here are specific criteria to look for:
- Native integrations: Look for a column-level lineage tool that provides 'set-it-and-forget-it' native integrations with your existing technology stack. It should connect with various databases, data warehouses, ETL tools, and BI platforms without extensive manual configuration. The integrations should be deep and broad, capable of auto-discovering schemas, tables, and columns across different data stores and automatically tracking their lineage over time.
- Scalability and accuracy: The tool must maintain high accuracy in lineage information even as the scale of data grows. It should be able to handle billions of rows and thousands of tables without a drop in performance. If it has a robust backend architecture, it should be capable of processing large volumes of metadata. It should also have sophisticated algorithms that can accurately parse and interpret complex data transformations and the ability to update lineage maps in near real-time as changes occur.
- User experience: Despite the complexity of its operations, a good column-level lineage tool should present lineage information in a clear, visual format that is easy to navigate and understand (even for non-technical users). This should include graphical representations of data flows, easy-to-read lineage paths, and the ability to drill down into detailed metadata with a few clicks. The goal is to make the investigation of data flows as effortless as possible, minimizing the learning curve and enabling broader adoption across the organization.
- Workflow automation: The tool should use column-level lineage to trigger downstream notifications. For example, if a source data column changes, the tool should automatically alert the relevant teams or systems that rely on that data. This could be through integration with messaging platforms like Slack or Microsoft Teams, or even directly within data processing pipelines, ensuring that all dependent processes are updated or reviewed accordingly.
The First Step to Better Data Governance
Column-level lineage is an essential piece of proper data management and governance because it tracks the movement of data from its source to its destination. It provides valuable information about the origin and flow of data, enabling organizations to identify potential data quality issues—which is particularly important in complex data environments where data is stored and processed across multiple tools.
Ultimately, when you opt for a data catalog equipped with accurate column-level lineage, you reduce the opportunity for manual errors and save on resources in the long term.
Want to see if Select Star is the right column-level lineage tool for your organization? Book a demo with one of our experts.